欢迎访问企鹅电竞在线观看官网,客服在线等待您哦
全国咨询热线:
13359207812

 企鹅电竞在线观看免费视频-新闻资讯
企鹅电竞在线观看免费视频-新闻资讯 企鹅电竞在线观看免费视频-新闻资讯
企鹅电竞在线观看免费视频-新闻资讯泡泡网显卡频道1月6日作为显卡来说,AMD的Radeon自HD4000时代以来为游戏玩家提供了众多优秀的产品,HD5000/HD6000系列丝毫不输给NVIDIA同级产品,性能、功能、价格、功耗等各方面表现得都很不错。对于AMD下代HD7000系列,我们毫不怀疑它在3D游戏中会有更出色的表现。
但作为GPU来说,AMD的产品显然要逊色很多,不支持物理加速、Stream通用计算性能不如CUDA,支持GPU加速的软件也屈指可数,这已经成为AMD最大的软肋,并且成了NVIDIA和NFan们攻击的对象。

随着时间的推移,保守的AMD终于尝到了固步自封的苦果:当NVIDIA的CUDA计算课程进入高校学堂、Tesla杀进超级计算市场、Quadro拿下95%的专业卡市场份额之时,AMD的Radeon还只能游弋在3D游戏领域,苦守来之不易的半壁江山。
想当年AMD率先提出GPU通用计算的概念,但最终却在NVIDIA的CUDA手中发扬光大。很多人以为这是AMD收购ATI后自顾不暇的关系,其实根本原因还在于GPU的架构——传统基于3D图形处理的GPU不适合于进行大规模并行计算,AMD的GPU拥有恐怖的理论运算能力却无从释放。而NVIDIA则从G80时代完成了华丽的转身,逐步完善了硬件和软件的协同工作,使得GPU成为高性能计算必不可少的配件。

俗话说的好:苦海无涯、回头是岸,亡羊补牢、为时不晚。AMD终于在代号为Southern Islands(南方群岛)的新一代GPU中,启用的全新的架构,AMD称之为“Graphics Core Next”(GCN,次世代图形核心),并冠以革命性的称号。这是AMD收购ATI之后的近5年来第一次对GPU架构进行“伤筋动骨”的“手术”,而架构调整的核心内容则是为并行计算优化设计。
那AMD的“次世代图形核心”相比沿用了五年之久的架构到底有何改进?其并行计算性能相比对手NVIDIA有无优势?3D游戏性能会否受到影响呢?本文将为大家做一个全方位的解析,文中会穿插一些3D渲染原理以及显卡基础知识,并谈谈GPU图形与计算的那些事儿……
微软的DirectX 9.0C是一个神奇的图形API,自2004年首款DX9C显卡GeForce 6800 Ultra问世以来,至今已有将近8年时间,之后虽然微软发布了DX10、DX10.1、DX11、还有现在的DX11.1等多个新版本,但DX9C游戏依然是绝对主流,DX10以后的游戏全部加起来也不过几十款而已!
因此,当年的DX9C显卡之战,很大程度上决定了此后很多年的显卡研发策略。从最开始X800不支持DX9C对抗6800失利,到X1800支持DX9C却性能不济,再到X1900登上顶峰,还有半路杀出来XBOX360这个程咬金,ATI被AMD收购前的经历犹如过山车般惊险刺激!
DXC如此长寿的原因,相信游戏玩家们已经猜到了,那就是游戏主机太长寿了——微软XBOX360以及后来索尼PS3使用的GPU都是DX9C时代的产品。游戏开发商的主要盈利来源在主机平台,所以根本没心思把PC游戏做好,尤其对提高PC游戏的画面及引擎优化提不起兴趣,个别以高画质而著称的PC游戏倍受打击,很多DX10游戏续作倒退到DX9C就是很好的证明。


微软XBOX360的成功,给GPU供应商ATI发出了一个信号,那就是今后N年内的游戏都将基于XBOX360的硬件而开发。当时ATI与Xenos同时研发的一颗GPU代号为R580,俩者拥有相似的架构,而R580在当年也成为DX9C显卡的王者,这就让ATI更加坚定了维持现有架构不变的决心。
下面我们就来看看R580的核心架构,也就是当年的王者X1900XTX/X1950XTX所使用的GPU,后来次高端RV570核心(X1950Pro)的架构也类似。
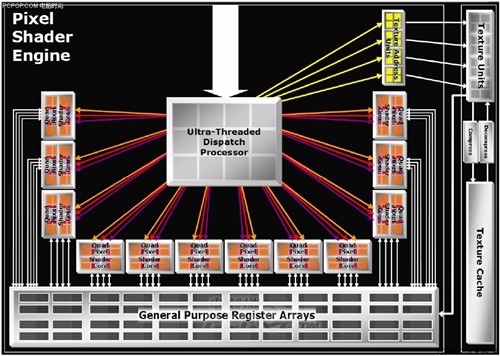
DX9C显卡还没有统一渲染架构的概念(XBOX360的Xenos是个特例),所以R580依然是顶点与像素分离式的设计。当时的GPU核心部分被称为管线条像素渲染管线条像素渲染管线,因为它的像素与纹理单元数量不对等。
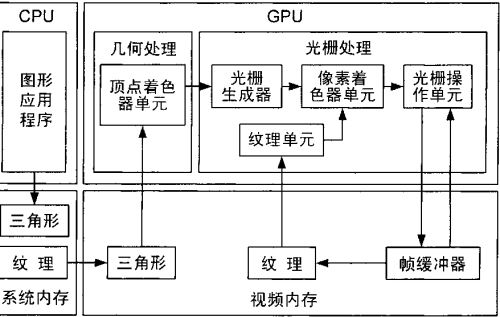
显卡的渲染流程是通过顶点单元构建模型骨架,纹理单元处理纹理贴图,像素单元处理光影特效,光栅单元负责最终的像素输出。
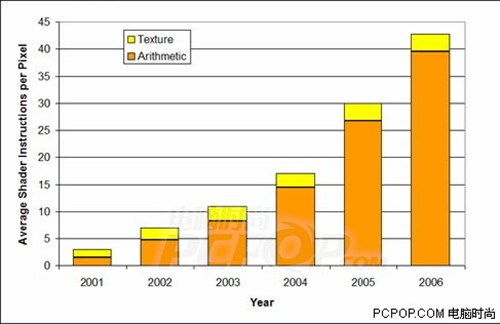
GPU的管线之前,GPU的像素单元与纹理单元还有光栅单元是绑定在一起的,数量一样多,整个渲染过程就是流水线作业,因此像素与纹理加起来称为一条管线XT)的像素与纹理都是16个,但R580核心在纹理单元维持16个不变的情况下,把像素单元扩充了3倍达到了48个之多。ATI研发工程师发现新一代游戏中使用像素着色单元的频率越来越高,各种光影特效(尤其HDR)吃掉了像素着色单元的所有资源,而纹理单元的负载并不高,继续维持像素与纹理1:1的设计就是浪费资源,于是ATI根据3D游戏引擎的发展趋势做出了改变,并把R580这种不对等的架构称之为3:1黄金架构,管线的概念至此消失。
像素(算数)与纹理的比例逐年提高当年ATI前瞻性的架构在部分新游戏中得到了应验,比如在优品飞车10、细胞分裂4、上古卷轴4等游戏中X1900XTX的性能远胜7900GTX。此外ATI专为HDR+AA优化的架构与驱动也让ATI风光无限。
但事实上,从1:1到3:1有点太激进了,在包括新游戏在内的绝大多数主流游戏中,都无法充分利用多达48个像素着色单元的能力。于是ATI的工程师们又有了新的想法:何不用这些像素单元来做一些非图形渲染的计算呢?像素单元的核心其实就是ALU(算术逻辑单元),拥有十分可观的浮点运算能力。
2006年9月,在X1900XTX发布半年之后,ATI与斯坦福大学相关科研人员合作,开发了首款使用GPU浮点运算能力做非图形渲染的软件——Folding @ Home第一代GPU运算客户端。

Folding@home是一个研究蛋白质折叠、误折、聚合及由此引起的相关疾病的分布式计算工程。最开始F@H仅支持CPU,后来加入了对PS3游戏机的支持,但同样是使用内置的CELL处理器做运算。F@H因ATI的加入为GPU计算翻开了新的一页,当然F@H加入了对NVIDIA DX10 GPU的支持那是后话。

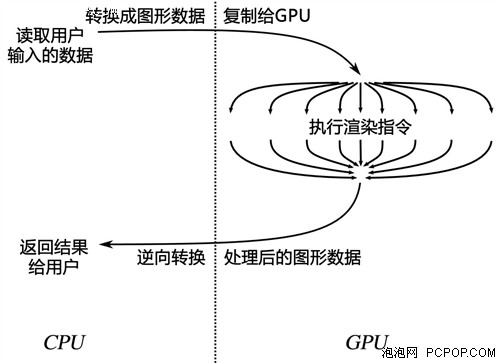
当时的GPU计算被称为GPGPU(General Purpose GPU),传统的图形处理器可以被用来做通用目的计算项目。所谓通用计算的大体流程就是:待处理的数据—〉转换成图形数据—〉GPU处理—〉处理后的图形数据—〉转换成所需数据。其实通用计算就是把数据转换为GPU能够“看懂”的图形数据,实际上是作为虚拟硬件层与GPU通讯,由于需要前后两次编译的过程,因此想要利用GPU强大的浮点运算能力,需要很强大的编译器,程序员的开发难度可想而知,CPU的运算量也比较大。
除了蛋白质折叠分布式计算外,当年ATI还开发了AVIVO Video Converter这款使用GPU加速视频转码的小工具,虽然效果一般,但也算是开了个好头。虽然GPU通用计算的实现难度很大,但至少GPU实现了非图形计算的目的,而且其性能确实要比当时的CPU快十几倍。小有所成的ATI被胜利冲昏了头脑,他们认为自己研发出了非常先进的、最有前瞻性的GPU架构,还找到了让GPU进行通用计算的捷径、还有了AMD这座靠山……最终促使AMD-ATI做出了保守的决定——下代GPU继续沿用R580的架构,不做深层次的改动。
R520-R580的成功,多达48个着色单元功不可没,这让ATI对庞大的ALU运算单元深信不疑。ATI认为只要继续扩充着色单元,就能满足新一代DX10及Shader Model 3.0的要求。
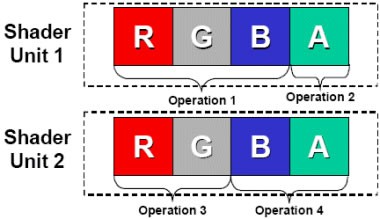
在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的运算器(ALU)。
数据的基本单元是Scalar(标量),就是指一个单独的值,GPU的ALU进行一次这种变量操作,被称做1D标量。由于传统GPU的ALU在一个时钟周期可以同时执行4次这样的并行运算,所以ALU的操作被称做4D Vector(矢量)操作。一个矢量就是N个标量,一般来说绝大多数图形指令中N=4。所以,GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是SIMD(Single Instruction Multiple Data,单指令多数据流)架构。
显然,SIMD架构能够有效提升GPU的矢量处理性能,由于VS和PS的绝大部分运算都是4D Vector,它只需要一个指令端口就能在单周期内完成4倍运算量,效率达到100%。但是4D SIMD架构一旦遇到1D标量指令时,效率就会下降到原来的1/4,3/4的模块被完全浪费。为了缓解这个问题,ATI和NVIDIA在进入DX9时代后相继采用混合型设计,比如R300就采用了3D+1D的架构,允许Co-issue操作(矢量指令和标量指令可以并行执行),NV40以后的GPU支持2D+2D和3D+1D两种模式,虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上分支预测的情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。
DX10时代,混合型指令以及分支预测的情况更加频繁,传统的Shader结构必须做相应的改进以适应需求。NVIDIA的做法是将4D ALU全部打散,使用了MIMD(Multi Instruction Multiple Data,多指令多数据流),而AMD则继续沿用SIMD架构,但对Shader微架构进行了调整,称为超标量架构。
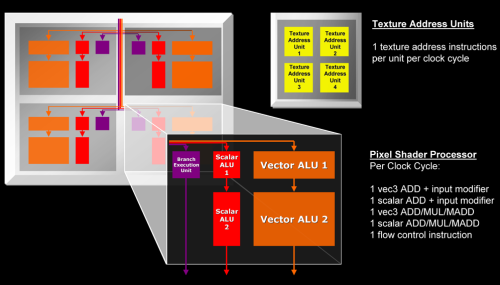
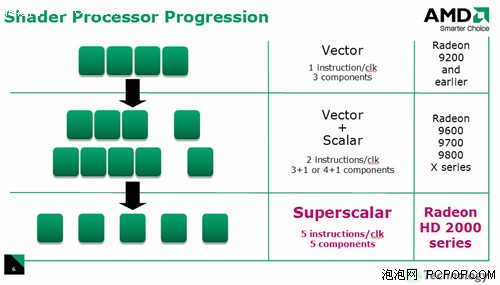
作为ATI的首款DX10 GPU,架构上还是有不少改进的,DX10统一渲染架构的引入,让传统的像素渲染单元和顶点渲染单元合二为一,统称为流处理器。R600总共拥有64个Shader单元,每个Shader内部有5个ALU,这样总计就是320个流处理器。
R600的Shader有了很大幅度的改进,总共拥有5个ALU和1个分支执行单元,这个5个ALU都可以执行加法和乘加指令,其中1个胖的ALU除了乘加外之外还能够进行一些函数(SIN、COS、LOG、EXP等)运算,在特殊条件下提高运算效率!

与R580不同的是,R600的ALU可以在动态流控制的支配下自由的处理任何组合形式的指令,诸如1+1+1+1+1、2+2+1、2+3、4+1等组合形式。所以AMD将R600的Shader架构称作Superscalar(超标量),完美支持Co-issue(矢量指令和标量指令并行执行)。
从Shader内部结构来看,R600的确是超标量体系,但如果从整个GPU宏观角度来看,R600依然是SIMD(单指令多数据流)的VLIW(超长指令集)体系:5个ALU被捆绑在一个SIMD Shader单元内部,所有的ALU共用一个指令发射端口,这就意味着Shader必须获得完整的5D指令包,才能让内部5个ALU同时运行,一旦获得的数据包少于5条指令,或者存在条件指令,那么R600的执行效率就会大打折扣。
HD2900XT的失败来自于很多方面,GPU核心架构只是冰山一角,就算保守的AMD沿用了DX9C时代的老架构,性能也不至于如此不济。但无奈GPU架构已经定型,短期内是无法改变了,HD2000和HD3000一败涂地,AMD咬牙硬抗了两年之久。就在大家为R600的架构争论不休,大谈VLIW指令集的弊端有多么严重时,AMD终于迎来了翻身之作——RV770核心。
虽然对流处理器部分没有改动,但AMD对流处理器以外的几乎所有模块都进行了改进,从而使得性能和效率有了质的提升,具体改动如下:
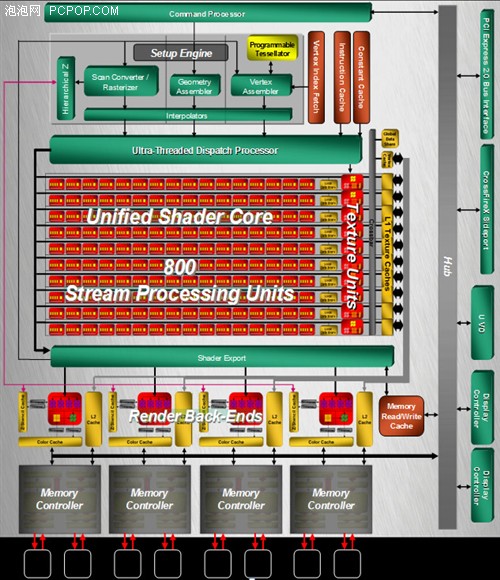
在纹理单元与显存控制器之间设有一级缓存,RV770核心相比RV670,L1 TC容量翻倍,再加上数量同比增加2.5倍,因此RV770的总L1容量达到了RV670/R600的五倍之多!
放弃环形显存总线,改用交叉总线还放弃了使用多年的环形显存总线,估计是因为高频率下数据存取命中率的问题,回归了交叉总线设计,有效提高了显存利用率,并节约了显存带宽。还有GDDR5显存的首次使用,瞬间将显存位宽翻倍,256Bit GDDR5的带宽达到了当时N卡512Bit GDDR3的水平。
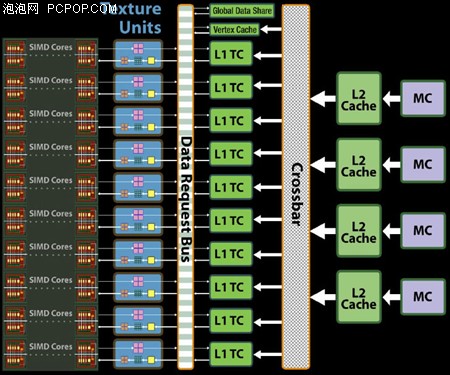
HD4870/HD4850打了一场漂亮的翻身仗,也让唱衰VLIW的人看傻了眼,之前大家普遍认为R600/RV670失败的主要原因是VLIW的低下效率,事实证明VLIW并没有错,其效率问题并没有严重到失控的地步,毕竟DX9C游戏还是主流,顶点与像素操作指令还是大头。AMD只是错误的判断了抗锯齿的算法和效率,导致第一代DX10 GPU性能不如预期。但最关键的问题不在3D游戏性能方面,AMD对GPU并行计算依然没有投入足够多的重视,AMD一方面在鼓吹自家Stream通用计算并不输给CUDA,各种商业软件未来将会加入支持,另一方面GPU架构未做任何调整,API编程接口支持也举步维艰。结果就是Stream软件无论数量、质量、性能还是发布时间都要远远落后于CUDA软件。
R600的失败让AMD明白了一个道理:从哪跌倒要从哪爬起来;RV770的成功让AMD坚信:我们的架构是没有问题的,以前的失败只是一个小小的失误,R600的架构前途无量,应该加快脚步往前冲……于是乎RV870诞生了。
如果说RV770是翻身之作,那么RV870(Cypress)就是反攻之作,AMD抢先推出DX11显卡,在NVIDIA GF100陷入大核心低良率的泥潭时,大举收复失地。
RV870是AMD近年来最成功的一颗GPU核心,但它的成功是拜NVIDIA的失误所赐,RV870核心本身可以说是毫无新意,因为它完全就是RV770的两倍规格,除了显存控制器以外的所有模块统统翻倍,AMD沿用RV770暴力扩充流处理器的路线,继续提高运算能力,抢滩登陆DX11。
既然流处理器部分还是维持R600的设计,那就不用期待它在并行计算方面能有什么改进。AMD依然我行我素的在搞通用计算,支持的软件还是那么几款。RV870理论浮点运算能力再创新高,但却没什么人用,中国最强的超级计算机天河一号曾经使用的是HD4870X2,但后来升级成天河一号A之后改用了NVIDIA的Tesla,就是活生生的例子。

Barts核心的HD6870率先问世,这颗核心定位中端,所以流处理器从Cypress的1600个精简到了1120个,流处理器结构依然没有任何变化,但是前端控制模块一分为二:
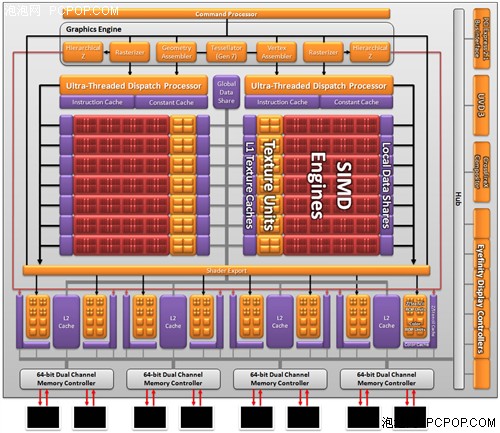
但随着晶体管规模和流处理器数量的迅速膨胀,单一的控制单元已经无法满足大规模并行指令分配的需要,因此从Cypress开始,AMD采用了“双核心”的设计,

Barts和Cypress一样,依然保持了双核心设计,图形引擎也只有一个,内部的功能模块并没有太多变化。但是Ultra-Treaded Dispatch Processor(超线程分配处理器)却变成了两个,相对应的,超线程分配处理器的指令缓存也变成了两份。Barts的图形装配引擎
我们知道,Barts的流处理器数量是Cypress的70%,按理说线程分配压力有所下降,那么设计两个线程分配处理器的目的只有一个,那就是提升效率。在DX11时代,几何着色再加上曲面细分单元引入之后,图形装配引擎会产生更多的并行线程及指令转交SIMD进行处理,因此指令派发效率成为了新的瓶颈。
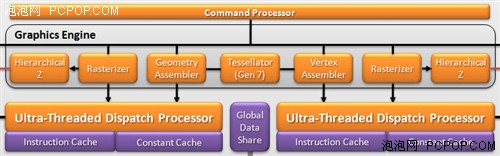
HD6000系列可以说是半代改进的架构,既然数量上维持不变,就只能从改进效率的方面考虑了。而改进的内容就是加强线程管理和缓冲,也就是“双倍的超线程分配处理器和指令缓存”。
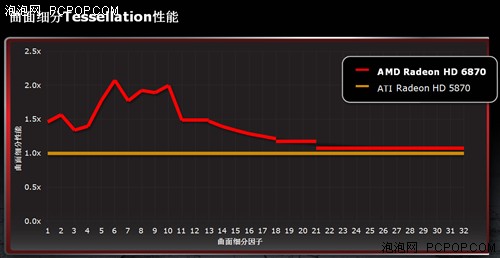
由此可见,Barts核心当中的Tessellator单元本身在性能方面应该没有改进,其性能提升主要源于两颗超线程分配处理器。中等级别的曲面细分在指令分配方面是瓶颈,Barts改进的架构消除了这一瓶颈,所以性能提升十分显著,但如果细分级别特别高时,Tessellator本身的运算能力将成为瓶颈,此时线程派遣器的效率再高,也无济于事。
看起来,AMD迫切的想要改进指令派发效率,以满足庞大规模流处理器的胃口,并且有效的提升备受诟病的曲面细分性能。AMD的做法就是继续保持现有架构不变,发现瓶颈/缺陷然后消除瓶颈/缺陷,这让笔者想起了一段老话:“新三年旧三年,缝缝补补又三年”。
相信有些读者很早就想问这样一个问题了:既然图形渲染的主要指令是4D矢量格式,那为什么R600要设计成5D的流处理器结构呢?还沿用了5代之久?有结果就有原因,通过对Cayman核心的分析,我们可以找到答案。R600为什么是5D VLIW结构?
在5D VLIW流处理器中,其中的1个比较“胖”的ALU有别于其它4个对等的ALU,它负责执行特殊功能(例如三角函数)。而另外4个ALU可以执行普通的加、乘、乘加或融合指令。
Cayman核心返璞归线大行其道,AMD通过自己长期内部测试发现,VLIW5架构的五个处理槽中平均只能用到3.4个,也就是在游戏里会有1.6个白白浪费了。显然,DX9下非常理想的VLIW5设计已经过时,它太宽了,必须缩短流处理器单元(SPU),重新设计里边的流处理器(SP)布局。
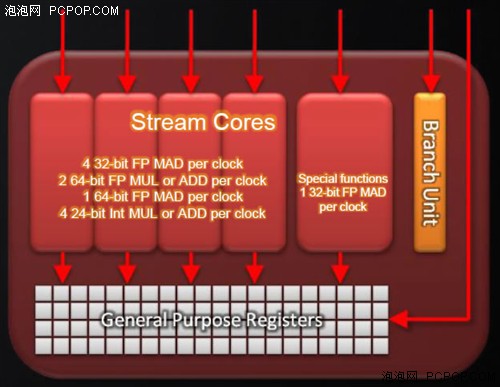
于是Cayman核心诞生了,胖ALU下岗,只保留了剩下4个对等的全功能ALU。裁员归裁员,原来胖ALU的工作还得有人干,Cayman的4D架构在执行特殊功能指令时,需要占用3个ALU同时运算。
5D改4D之后最大的改进就是,去掉了体积最大的ALU,原本属于它的晶体管可以用来安放更多的SIMD引擎,据AMD官方称流处理器单元的性能/面积比可以提升10%。而且现在是4个ALU共享1个指令发射端口,指令派发压力骤减,执行效率提升。双精度浮点运算能力也从原来单精度的1/5提高到了1/4。
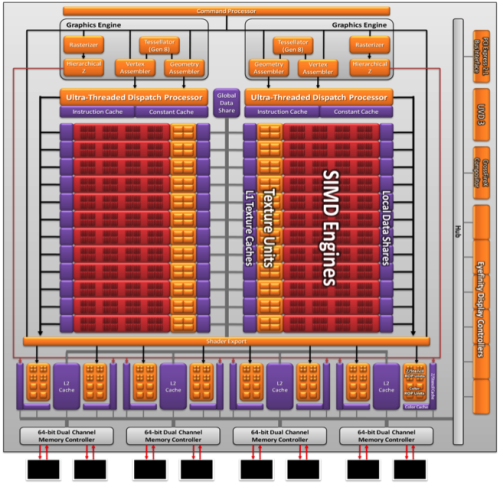
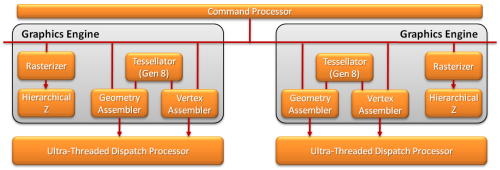
前面介绍过,从RV770到Cypress核心,图形引擎和超线程分配处理器都只有一个,但图形引擎内部的Hierarchical Z(分层消影器)和Rasterizer(光栅器)分为两份。
到了Barts核心,超线程分配处理器从一个变成两个。现在的Cayman核心则更进一步,图形引擎也变成了两个,也就是除了分层消影器和光栅器外,几何着色指令分配器、顶点着色指令分配器、还有曲面细分单元都变成了两份:

两个曲面细分单元再加上两个超线程分配处理器,AMD官方称HD6970的曲面细分性能可以达到HD6870的两倍、HD5870的三倍。其它方面比如顶点着色、几何着色性能都会有显著的提升。
和Cypress、Barts相比,Cayman在通用计算方面也有一定程度的改进,主要体现在具备了一定程度的多路并行执行能力;双路DMA引擎可以同时透过外部总线和本地显存读写数据;改进的流控制提高了指令执行效率和运算单元浪费;当然双精度运算能力的提高对于科学计算也大有裨益。
不过,这些改进都是治标不治本,VLIW架构从5D到4D只是一小步,只能一定程度上的提高指令执行效率,而无法根治GPU编程困难、复杂指令和条件指令的兼容性问题。总的来说,Cayman核心依然只是单纯为游戏而设计的GPU,AMD把5D改为4D也是基于提升3D渲染性能的考虑。
AMD的GPU架构介绍了这么多,对于其优缺点也心知肚明了,之前笔者反复提到了“效率”二字,其参照物当然就是NVIDIA的GPU,现在我们就来看看NVIDIA的GPU架构有什么特点,效率为什么会比较高?为什么更适合并行计算?
无论AMD怎么调整架构,5D还是4D的结构都还是SIMD,也就是这4-5个ALU要共用一个指令发射端口,这样就对GPU指令派发器提出了很高的要求:如果没有把4-5个指令打包好发送到过来,那么运算单元就不会全速运行;如果发送过来的4-5个指令当中包含条件指令,但运行效率就会降至连50%都不到,造成灾难性的资源浪费。
解决方法也不是没有,但都治标不治本,需要对游戏/程序本身进行优化,尽量避免使用标量指令、条件指令和混合指令,驱动为程序专门做优化,难度可想而知。
NVIDIA的科学家对图形指令结构进行了深入研究,它们发现标量数据流所占比例正在逐年提升,如果渲染单元还是坚持SIMD设计会让效率下降。为此NVIDIA在G80中做出大胆变革:流处理器不再针对矢量设计,而是统统改成了标量ALU单元,这种架构叫做MIMD(Multiple Instruction Multiple Data,多指令多数据流)
如此一来,对于依然占据主流的4D矢量操作来说,G80需要让1个流处理器在4个周期内才能完成,或者是调动4个流处理器在1个周期内完成,那么G80的执行效率岂不是很低?没错,所以NVIDIA大幅提升了流处理器工作频率(两倍于核心频率),扩充了流处理器的规模(128个),这样G80的128个标量流处理器的运算能力就基本相当于传统的64个(128×2?)4D矢量ALU。大家应该知道R600拥有64个5D矢量ALU,最终的性能G80要远胜R600。
当然这只是在处理4D指令时的情形,随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与4D一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!
G80的架构听起来很完美,但也存在不可忽视的缺点:根据前面的分析可以得知,4个1D标量ALU和1个4D矢量ALU的运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构!
所以AMD的SIMD架构可以用较少的晶体管造出庞大数量的流处理器、拥有恐怖的理论浮点运算能力;而NVIDIA的MIMD架构必须使用更多的晶体管制造出看似比较少的流处理器,理论浮点运算能力相差很远。双方走的都是极端路线,AMD以数量弥补效率的不足,而NVIDIA以效率弥补数量的劣势。
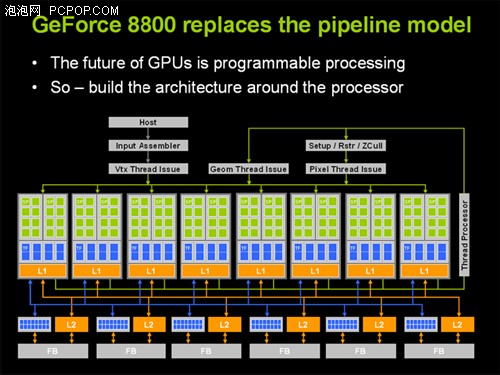
G80依然只是为DX10 3D渲染而设计的,虽然MIMD架构本身能够胜任并行数据计算的需要,但NVIDIA发现图形架构还有继续改进的余地,只要在核心内部设计全新的控制模块,并对微架构进行专门的优化,就能将GPU的图形架构改造成更加适合非图形领域的并行数据处理架构。
第一代统一渲染架构的主要目的是把原本像素着色、顶点着色以及新增的几何着色,统一交给流处理器来处理。而NVIDIA的GT200核心则被称为第二代统一渲染架构,其主要含义就是将图形处理架构和并行计算架构完美的结合起来,成为一颗真正意义上的通用处理器,超越图形处理器的概念!
每个SM可执行线核心每个SM(即不可拆分的8核心流处理器)最多可执行768条线拥有更多的SM,芯片实力达到原来的2.5倍!


:GTX200与G80核心在SM结构上基本相同的,但功能有所提升,在执行线程数增多的同时,NVIDIA还将每个SM中间的Local Memory容量翻倍(从16K到32K)。Local Memory用于存储SM即将执行的上千条指令,容量增大意味着可以存储更多的指令、超长的指令、或是各种复杂的混合式指令,这对于提高SM的执行效能大有裨益。

提高双指令执行(Dual-Issue)效率,达到93%-94%之多,支持双精度64Bit浮点运算
随着Tesla在高性能计算领域日渐深入人心,NVIDIA也在与科研工作者们进行深入的沟通,倾听一线用户的需求,以便在下代GPU核心中做出相应的优化改进。当时用户最大的需求有两点:第一,科学家和超级计算只看重64bit双精度浮点运算能力,GT200性能太低,只有单精度的1/8;第二:企业级用户对稳定性要求更高,传统的显卡不支持显存ECC(错误检查和纠正),计算出错后效率较低。

过于追求完美往往结果就会不完美,NVIDIA在GPU架构设计部分做到了近乎完美,但是在芯片制造端掉了链子——由于GPU核心太大,台积电40nm工艺还不够成熟,导致GF100核心良率低下,没能达到设计预期,最终的产品不仅功耗发热很大,而且规格不完整。所以虽然当时GTX480显卡的评价不是很高,但GF100核心的架构极其优秀的。等到工艺成熟之后的GF110核心以及GTX580显卡,就毫无疑问的站在了游戏与计算的巅峰!
GF100与GT200最大的不同其实就是PolyMorph Engine,译为多形体引擎。每个SM都拥有一个多形体引擎,GF100核心总共有多达16个。那么多形体引擎是干什么用的呢?为什么要设计如此之多?

之前的GPU架构一直都使用单一的前端控制模块来获取、汇集并对三角形实现光栅化。无论GPU有多少个流处理器,这种固定的流水线所实现的性能都是相同的。但应用程序的工作负荷却是不同的,所以这种流水线通常会导致瓶颈出现,流处理器资源未能得到充分利用。

Tessellation的使用从根本上改变了GPU图形负荷的平衡,该技术可以将特定帧中的三角形密度增加数十倍,给设置于光栅化单元等串行工作的资源带来了巨大压力。为了保持较高的Tessellation性能,有必要重新平衡图形流水线。
为了便于实现较高的三角形速率,NVIDIA设计了一种叫做“PolyMorph”的可扩展几何引擎。每16个PolyMorph引擎均拥有自己专用的顶点拾取单元以及镶嵌器,从而极大地提升了几何性能。与之搭配的4个并行光栅化引擎,它们在每个时钟周期内可设置最多4个三角形。同时,它们还能够在三角形获取、Tessellation、以及光栅化等方面实现巨大性能突破。

AMD的Cayman核心是不分光栅化引擎和多形体引擎的,都可以算作是双核心设计,GF100与Cayman相比,光栅化引擎是4:1,多形体引擎(包括曲面细分单元)是16:2,GF100的几何图形性能有多么强大已经可以想象。
当NVIDIA的工程师通过计算机模拟测试得知几何引擎将会成为DX11新的瓶颈之后,毫不迟疑的选择了将单个控制模块打散,重新设计了多形体引擎和光栅化引擎,并分散至每组SM或每个GPC之中,从而大幅提升了几何性能,彻底消除了瓶颈。

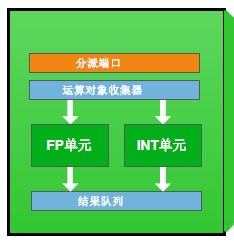
每一个CUDA核心都拥有一个完全流水线化的整数算术逻辑单元(ALU)以及浮点运算单元(FPU)。GF100采用了最新的IEEE754-2008浮点标准,2008标准的主要改进就是支持多种类型的舍入算法。新标准可以只在最终获取数据时进行四舍五入,而以往的标准是每进行一步运算都要四舍五入一次,最后会产生较大的误差。
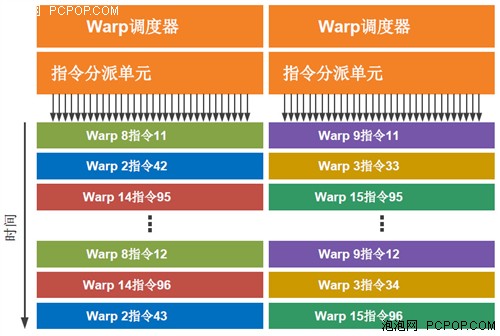
GF100拥有双Warp调度器可选出两个Warp,从每个Warp发出一条指令到16个核心、16个载入/存储单元或4个特殊功能单元。因为Warp是独立执行的,所以GF100的调度器无需检查指令流内部的依存关系。通过利用这种优秀的双指令执行(Dual-issue)模式,GF100能够实现接近峰值的硬件性能。
在GF100 GPU中,每个SM除了拥有专用的纹理缓存外,还拥有64KB容量的片上缓存,这部分缓存可配置为16KB的一级缓存+48KB共享缓存,或者是48KB一级缓存+16KB共享缓存。这种划分方式完全是动态执行的,一个时钟周期之后可自动根据任务需要即时切换而不需要程序主动干预。
一级缓存与共享缓存是互补的,共享缓存能够为明确界定存取数据的算法提升存取速度,而一级缓存则能够为一些不规则的算法提升存储器存取速度。在这些不规则算法中,事先并不知道数据地址。
对于图形渲染来说,重复或者固定的数据比较多,因此一般是划分48KB为共享缓存,当然剩下的16KB一级缓存也不是完全没用,它可以充当寄存器溢出的缓冲区,让寄存器能够实现不俗的性能提升。而在并行计算之中,一级缓存与共享缓存同样重要,它们可以让同一个线程块中的线程能够互相协作,从而促进了片上数据广泛的重复利用并减少了片外的通信量。共享存储器是使许多高性能CUDA应用程序成为可能的重要促成因素。GF100拥有一个768KB容量统一的二级高速缓存,该缓存可以为所有载入、存储以及纹理请求提供服务。二级缓存可在整个GPU中提供高效、高速的数据共享。物理效果、光线追踪以及稀疏数据结构等事先不知道数据地址的算法在硬件高速缓存上的运行优势尤为明显。后期处理过滤器需要多个SM才能读取相同的数据,该过滤器与存储器之间的距离更短,从而提升了带宽效率。
统一的共享式缓存比单独的缓存效率更高。在独享式缓存设计中,即使同一个缓存被多个指令预订,它也无法使用其它缓存中未贴图的部分。高速缓存的利用率将远低于它的理论带宽。GF100的统一共享式二级高速缓存可在不同请求之间动态地平衡负载,从而充分地利用缓存。二级高速缓存取代了之前GPU中的二级纹理缓存、ROP缓存以及片上FIFO。
而且是完全一致的。NVIDIA采用了一种优先算法来清除二级缓存中的数据,这种算法包含了各种检查,可帮助确保所需的数据能够驻留在高速缓存当中。
之所以要对NVIDIA的GF100/110核心进行重点介绍,是因为它是一个很好的参照物,接下来要介绍的Tahiti核心很多方面都会与GF100进行对比,看看AMD所谓的GCN(次世代图形核心)到底有多么先进。

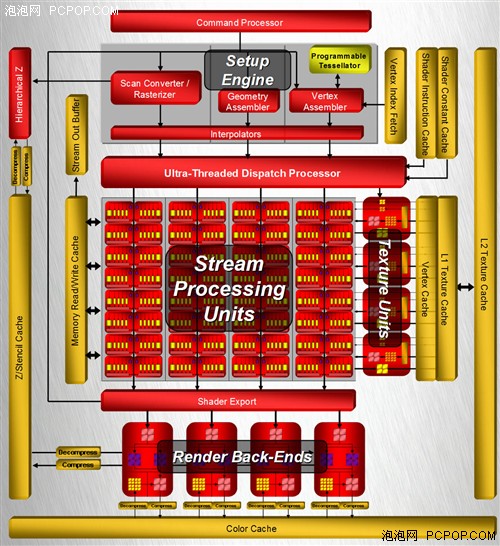
这是AMD官方公布的Tahiti核心架构图,第一眼看上去,我们就会发现他与以往所有的AMD GPU架构有了明显区别,无论图形引擎部分还是流处理器部分都有了天翻地覆的变化,如果没有右侧熟悉的UVD、CrossFire、Eyefinity等功能模块,很难相信这是一颗AMD的GPU。
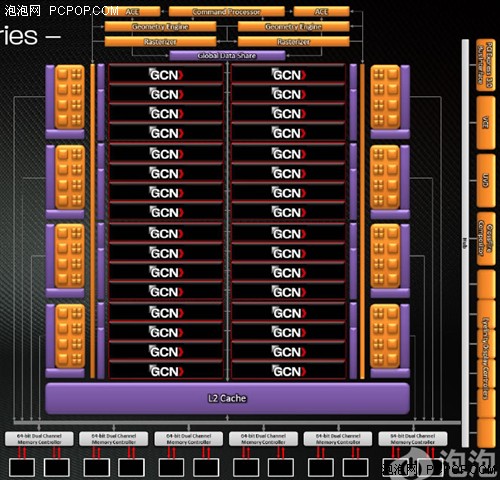
这一部分Tahiti几乎没有什么变化,依然是双图形引擎的设计,几何着色指令分配器、顶点着色指令分配器、曲面细分单元、光栅器、分层消影器都是双份的设计。
除此之外,还有一个毫不起眼但是意义重大的改进,那就是在图形引擎上方加入了两个ACE(Asynchronous Compute Engine,异步计算引擎),这两个引擎直接与指令处理器、几何引擎及全局数据缓存相连,作用是管理GPU的任务队列,将线程分门别类的分发给流处理器。
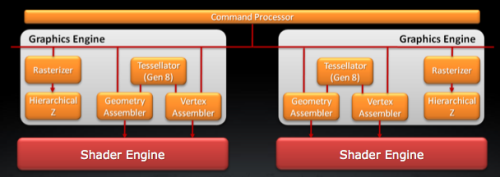
ACE将会充当指令处理器的角色用于运算操作,而ACE的主要作用就是接受任务并将其下遣分配给流处理器(主要是分配的过程)。全新架构强化了多任务的并行处理设计,资源分配、上下文切换以及任务优先级决策等等。ACE的直接作用就是新架构拥有了一定程度的乱序执行能力,虽然严格意义上新架构依然是顺序执行架构,一个完整线程中的指令执行顺序不能被打乱,但是ACE可以做到对不同的任务进行优化和排序,划分任务执行的优先级别,进而优化资源。从本质上来说,这与很多CPU(比如Atom、ARM A8等等)处理多任务的方式并没有什么不同。
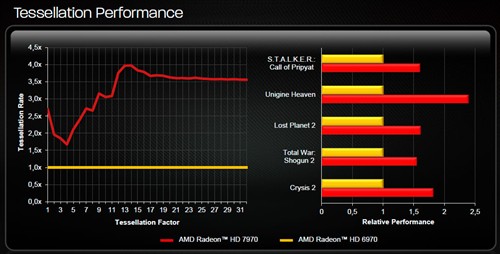
单从数量上来看,Tahiti明显不如GF100的4个光栅化引擎(光栅器+分层消影器)以及8个多形体引擎(几何/顶点分配器及曲面细分单元等)。不过AMD有针对性的强化了曲面细分单元,通过提高顶点的复用率、增强片外缓存命中率、以及更大参数高速缓存的配合下,HD7970在所有级别的曲面细分环境下都可以达到4倍于HD6970的性能:

看得出来,AMD的Tahiti在图形引擎方面依然沿用Cayman的设计,从Cypress到Barts再到Cayman,AMD稳扎稳打的对图形引擎进行优化与改进,AMD认为现有的双图形引擎设计足以满足流处理器的需要,因此只对备受诟病的曲面细分模块进行了改良,如此有针对性的设计算是亡羊补牢、为时不晚。
Tahiti的GCN阵列微观结构GCN阵列里有4组SIMD单元,每组SIMD单元里面包括16个流处理器、或者说是标量运算器。GCN架构已经完全抛弃了此前5D/4D流处理器VLIW超长指令架构的限制,不存在5D/4D指令打包-派发-解包的问题,所有流处理器以16个为一组SIMD阵列完成指令调度。简单来说,以往是指令集并行,而现在是线程级并行。

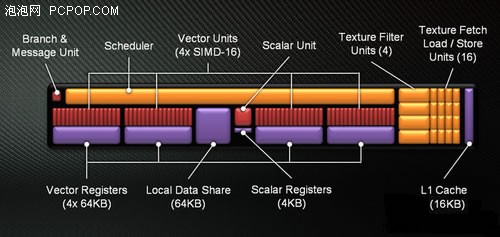
每组GCN阵列有一个标量运算单元,用于执行整数指令、媒体指令和浮点原子操作,这个标量运算单元拥有自己的4KB寄存器
而GF100的缓存设计得更加灵活,每组SM里面拥有总计64KB的共享缓存+一级缓存,这64KB缓存可以根据实际运算量来动态调整,如果把16KB分配给一级缓存的线KB就是共享缓存,反之亦然。
一般来说,进行图形渲染时需要共享缓存比较多,而并行计算时则会用到更多的一级缓存。GF100这种灵活的缓存分配机制更适合做并行计算,而GCN架构更大的共享缓存会有更好的图形渲染性能,并行计算则会稍逊一筹。
从缓存部分的设计来看,虽然GCN拥有更大的缓存容量,但在并行计算领域经营多年的NVIDIA显然要棋高一手。
从线程级别来看,GCN与SM是不可分割的最小单元,GCN一次可以执行64个线个(其实就是流处理器的数量)。
从多线程执行上来看,GCN可以同时执行4个硬件线程,而SM是双线程调度器的设计(参见架构图)。
在流处理器部分,终于不用费劲的把AMD和NVIDIA GPU架构分开介绍了,因为GCN与SM已经没有本质区别。剩下的只是缓存容量、流处理器簇的数量、线程调度机制的问题,双方根据实际应用自然会有不同的判断,自家的前后两代产品也会对这些数量和排列组合进行微调。AMD向NVIDIA的架构靠拢,证明了他这么多年来确实是在错误的道路上越走越远,还好浪子回头金不换,这次GCN架构简直就是!
在流处理器部分,我们看到Tahiti与GF100如此相似,那么接下来看到缓存设计时,您可能会要惊呼了……看图说话:
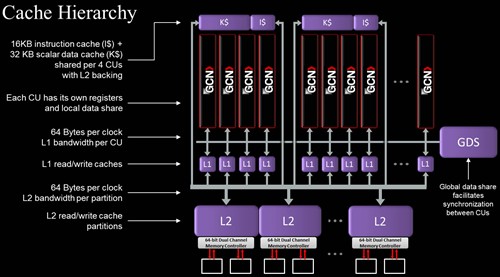
上页说过,Tahiti的每组GCN阵列拥有16KB的一级缓存,GF100的SM里面也有16KB的一级缓存;每组GCN拥有64KB的本地数据共享缓存,GF100的每组SM拥有48KB。
Tahiti总共拥有32个GCN阵列,所以一级缓存共有512KB,而GF100拥有16个SM阵列,一级缓存共有256KB。但别忘了GF100的L1可以是48KB,这样总共就是768KB了。


Tahiti的每组GCN需要将16KB一级缓存当作纹理缓存使用,而GF100的每组SM当中设有专用的12KB纹理缓存;一般来说非图形渲染不需要用到纹理缓存,而图形渲染时又不会用到一级缓存,所以Tahiti将一级缓存与纹理缓存合并的设计更优;但NVIDIA专门设计纹理缓存也不是没有道理,当GPU既渲染图形又要做计算时,分离式设计的效率会更高,比如PhysX游戏……A卡不支持所以AMD不会考虑这种情况。
Tahiti整个GPU拥有一个32KB的全局数据共享缓存,这个是沿用了Cayman的设计,但容量减半了,而GF100没有这种缓存。全局数据共享缓存主要用于不同GCN阵列间线程的数据交换,这块缓存只对编译器可见,所以使用率较低,容量减半相信也是处于这个原因。

至于PCI-E 3.0总线的支持,更是超前,目前只有Intel的X79+i7-3960X平台才会提供PCI-E3.0支持。根据经验来判断,PCI-E 3.0翻倍的带宽并不会给显卡带来性能提升,其主要意义还是对于多卡的支持。试想,如果PCI-E 3.0 X4都可以满足HD7970的需求的线(搭配IvyBridge处理器)就不会限制多路交火的性能表现,而X79插8块(如果主板有这么多插槽的线做并行计算也不会因为接口带宽而产生性能瓶颈。

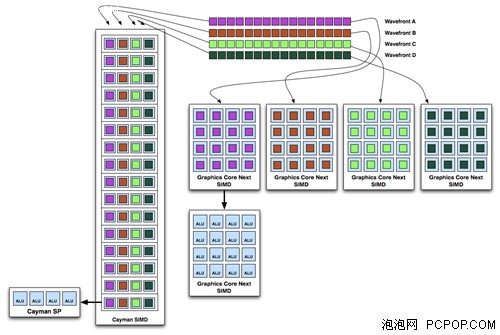
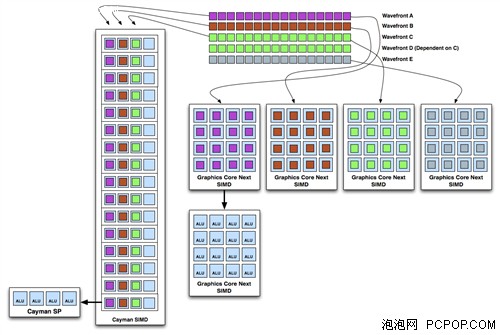
但对于VLIW架构来说,不理想的情况就是遇到相关的指令流,比如两个绿色线程,前三个线程可在一个周期内执行,最下方的蓝色只能独立执行。而对于新架构来说,则不存在这样的问题。也就是说,采用硬件调度之后,GCN和SIMD可以允许选择不同的线程乱序执行,这些线程可以来自同一任务,也可以是不同任务。当然,这种“乱序”也不是绝对的,基本的流程还是要遵守的,比如各个线程之间的指令必须按顺序执行,不能打乱也不能分割。
以上就是AMD官方提供的数据,HD7970的理论运算能力相比HD6970提升不过30%,但在GPU计算应用当中的性能提升相当显著,可达两倍以上!尤其在AES加密解密算法中,速度达到了4倍以上,架构的威力可见一斑!

以往的VLIW架构在并行任务处理方面处于劣势,并且很依赖编译器和API的支持,扩展到OpenCL也受到很大限制。经过硬件架构的调整,新的GCN架构在并行计算方面有了很大提高。编译压力减轻,硬件调度的加入使编译器摆脱了调度任务;其次是程序优化和支持语言扩充更见容易;最后是不用在生成VLIW指令和相关调度信息,新架构最底层的ISA也更加简单。

从DX10时代开始,也就是ATI被AMD收购之后,AMD的GPU架构一直都没有大的改动。从HD2000到HD6000,大家应该会发现GPU流处理器部分的结构没有任何改动,区别只是规模而已。这次AMD能够彻底抛弃沿用了5年之久的VLIW超长指令集架构,真的是让人眼前一亮,真可谓是浪子回头金不换。

Tihiti的GPU架构改得很彻底,换句话说就是AMD学得很快,NVIDIA花了5年时间循序渐进的把G80进化到了GF100的级别;而AMD只用了一年时间,就让Tahiti达到甚至部分超越了GF100的水平,真是可喜可贺!
但是AMD还有很长的路要走,硬件虽然很强大、全新的GCN架构也扫清了效率低下障碍,但软件和程序方面还需加把劲。让AMD欣喜的是OpenCL API的发展速度比想象中的还要快,以至于NVIDIA打算部分开放CUDA接口。可以预见的是,未来更多的商业软件将会直接使用OpenCL语言编写,对于GPU实现无差别的硬件加速支持,最终比拼的还是架构与效率,而不是谁支持的软件更多一些。

随着GPU架构越来越复杂,传统“半年更新,一年换代”的已经过时,再加上先进制造工艺的步伐放缓,GPU架构更新的周期被大大延长(1年、2年或者更长),我们现在看到的GPU大多是在原有架构上“缝缝补补”。对于现代GPU来说,一次换代并不仅仅是硬件架构的革新,更多时间的是开发者们对新架构的适应以及对新特性的吸收。
随着技术的发展,图形和计算的概念已经不再像以往分的那么清楚了,进入DX11时代时候,全新API和新特性带来了以往DirectX版本看不到的东西,尤其是大量的图形特效可以靠GPU的计算能力进行加速,这一切在要求传统图形渲染能力的同事,对GPU的计算能力要求十分苛刻,而未来图形架构的发展势必会顺应这一趋势。由此看来,AMD下定决定进行大规模的架构革新也就不奇怪了。

基于GCN架构、Tahiti核心的Radeon HD 7970显卡将在北京时间1月9日下午1时正式发布,由于国外提前发布的关系,可能很多朋友已经看过国外的测试成绩了,但我们将为读者们献上最全面的3D游戏性能测试以及并行计算性能测试,关注GPU图形与计算的朋友不容错过,敬请期待!■

